YOLOv8详解
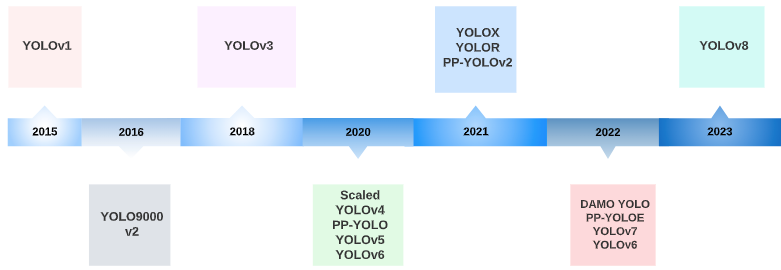
1. YOLOV8 概述
整体网络在YOLOV5的基础上进行了优化,并结合了YOLOV7的ELAN算法思想,基于缩放系数提供了n/s/m/l/x五种参数量依次增大的模型,并通过一套框架实现实例分割、姿势/关键点检测、目标检测和分类支持多种复杂任务[1]。

2. YOLOv8检测算法整体模型结构
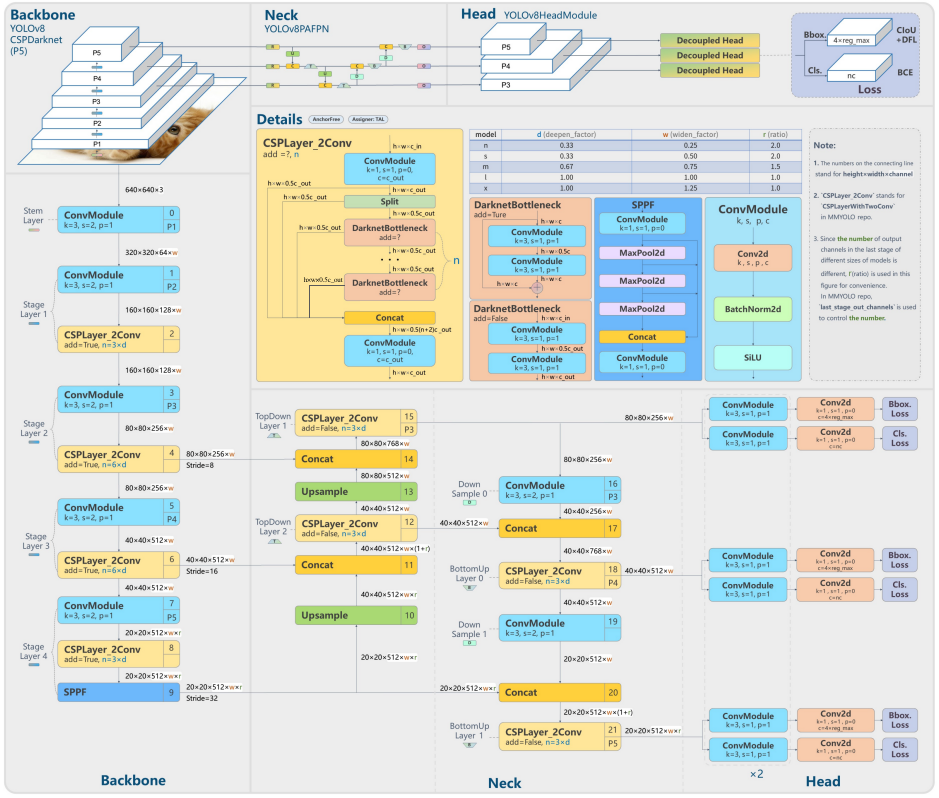
从两个模型的yaml文件可以看出,不同尺度大小的模型,yolov5的最大通道采用了统一大小的最大通道,均为1024,yolov8中n/s、l/x分别采用了相同大小的最大通达,s/m/l则进行了精调, 主要目的是为了平衡各个模型的参数量。

2.1 Backbone
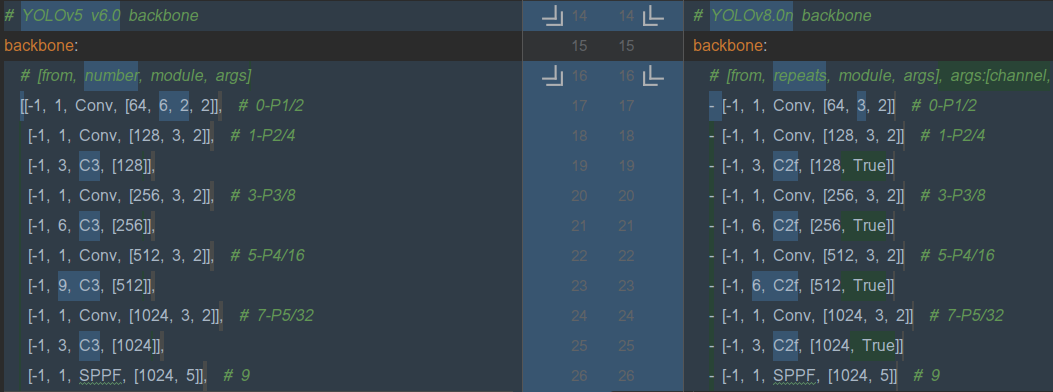
Backbone中yolov5和yolov8主要有两点差异:
(1)提取初步特征的第一个卷积层的卷积核kernel,yolov5为6x6, yolov8为3x3,感受野相比于yolov5进一步缩小[2]。
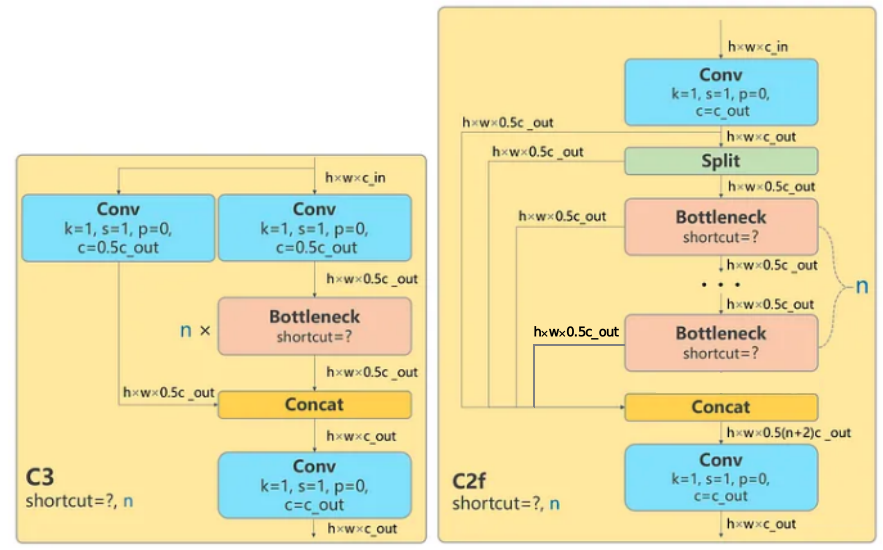
(2)yolov5中的C3模块在yolov8中被替换为了C2f,C2f则采用了yolov7中ELAN 多层堆叠的结构,增加了更多类似resnet残差块中的跳跃连接,丰富了模型的梯度流。
2.1.1 SPPF模块
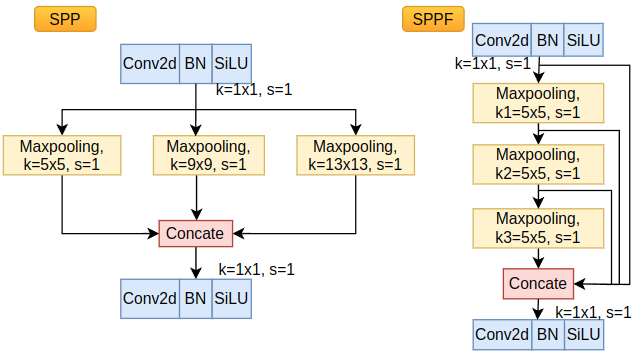
SPP与SPPF有着相同的作用:实现多尺度特征融合。原始的SPP模块是由Joseph Redmon 在 YOLOv3 中实现的,采用不同大小池化kernel的并行结构,而SPPF首次使用是在YOLOv5中,采用了三个相同大小池化Kernel的并行+串行的结构, 增加了更多的跳跃连接。 为什么左侧SPP的Maxpooling,其kernel size分别是5,9,13, 而右侧SPPF的kernel size均是5呢?我们用感受野的公式计算一下感受野: \[\begin{aligned}r_l&=r_{l-1}+\left((k_l-1)*\prod_{i=1}^{l-1}s_i\right), l>=2\end{aligned}\tag{1}\] 其中: \(r_{l}\)为第\(l\)层的感受野, \(k_l\)为第\(l\)层的kernel size,\(s_i\)为步长stride。 假设conv2d+BN+SiLU为第一层,令\(r_{1}\)为1,则有:
| 右侧 | 左侧 |
|---|---|
| \(r_{k_1=5}\)= 1+4*1=5 | \(r_{k=5}\) = 1+4*1=5 |
| \(r_{k_2=5}\)= 5+4*1=9 | \(r_{k=9}\) = 1+8*1=9 |
| \(r_{k_3=5}\)= 9+4*1=13 | \(r_{k=13}\) = 1+12*1=13 |
可以发现SPP和SPPF有着相同的感受野,但SPPF的浮点运算量更少,所以速度更快[3]。
2.2 Neck
Neck部分采用FPN和PAN结合的结构,实现浅层特征与深层特征的相互融合,共提取三个有效特征层给Head: feat1=(80, 80, 256\(w\))、feat2=(40, 40, 512\(w\))、feat3=(20, 20, 512\(*w*r\)){其中\(w,r\)为模型系数}, 并将三个特征层作为Head的输入。
2.3 Head
 |
|---|
 |
 |
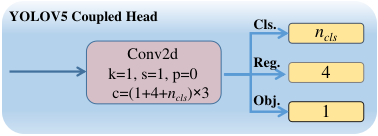
yolov5、yolox和yolov8三者的Head中,yolov5为ancher base,yolov8和yolox为ancher free, 并且yolov8和yolox均用了decoupled detection head(两个并行分支分别完成检测和分类,yolox的论文显示采用decoupled detection head能够提升AP约1.1个百分点[4]),预测输出方面:
yolov5: 对于特征图上的每一个grid cell预测(\(N_{cls}\) + 4 + 1)x3个参数,其中\(N_{cls}\)表示类别数,4表示网络预测bbox的相关参数,1表示是否有目标。
yolox: 对于特征图上的每个grid point预测(\(N_{cls}\) + 4 + 1)个参数。\(N_{cls}\)、4、1的含义和yolov5相同。对于有80个类别的coco数据集, 三个检查头所预测的参数个数分别为80x80x(80 + 4 + 1)、40x40x(80 + 4 + 1)、20x20x(80 + 4 + 1)个参数。
yolov8: yolov8消除了yolox中判断是否有物体的obj. 分支, 对于特征图上的每个特征点预测(\(N_{cls}\) + 4* \(\text{reg_max}\))个参数,在yolox中分类和回归分支的通道数均为256,yolov8认为作为两个不同的分支,用于表征不同的特征,通道数不应该是相等的[5],对于分类分支通倒数\(C_{cls}\) 设置为\(max(C^{3},min(N_{cls},100))\),回归分支的通道数\(C_{reg}\)为\(max(16,C^{3}/4,4*\text{reg_max})\)。对于有80个类别的coco数据集,假设设\(\text{reg_max}\) 为16,\(w\) 取1: \[ \begin{aligned} &C_{cls}=max(256,min(80, 100))=256 \\ &C_{reg}=max(16,256/4,4*16)=64 \end{aligned} \] 对于YOLOv8两个分支最后的Conv2d模块:
类别预测分支输出的维度为:
\([B,N_{cls},H,W]\)
回归预测分支的输出维度为:
\([B,4*\text{reg_max},H,W]\)
其中\(B\)为batch,\(H,W\)分别表示特征图高与宽
我们知道对于anchor free的模型,对于特征图上的每一个点期望预测4个bbox的参数,yolox所预测为\([t_x, t_y, t_w, t_h]\)[6],yolov8参考FCOS[7]预测的为\([l, t,r , b]\),具体如下图:
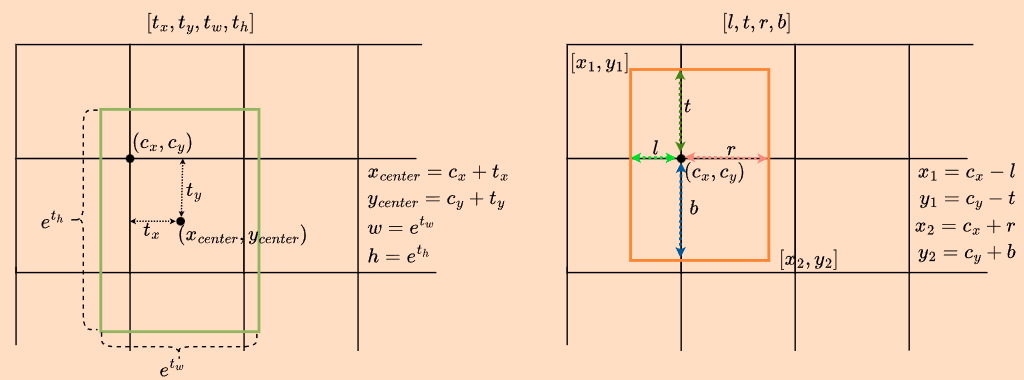
而和FCOS不同的是,yolov8并没有直接预测\([l, t,r , b]\)的值,而是采用Generalized Focal Loss[8]中的Distribution Focal Loss(DFL)通过预测一个离散分布计算得到: \[\hat{y}=\sum_{i=0}^nP(y_i)y_i\tag{2}\] 由于是离散分布,所以有:\(\sum_{i=0}^nP(y_i)=1\)。 DFL的具体代码实现如下:
1 | |
在代码DFL的forward中,由于输入x的维度为\([B,4*\text{reg_max},H*W]\), 输出的维度为\([B,4,H*W]\)(其中4对应于\(l, t,r , b\)),如果\(\text{reg_max}\)=16, 则DFL的forward计算过程如下: 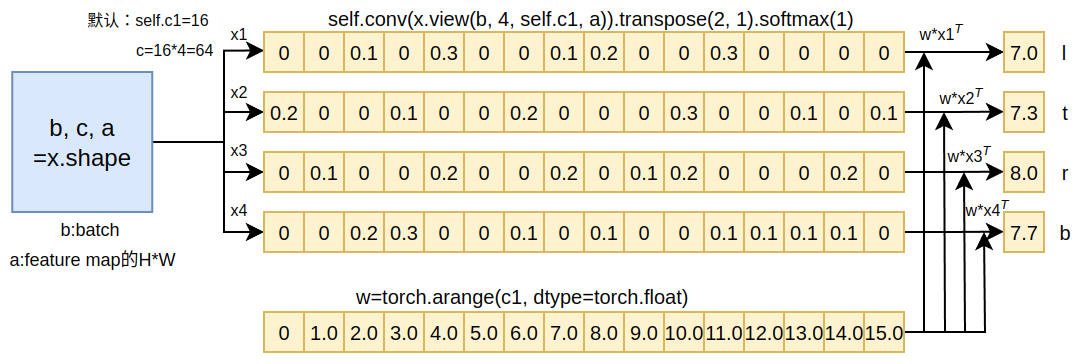
假设我们暂时不考虑上图计算过程的\(B\)和\(H*W\)维度, 计算过程大致为:如果\(x\)的shape为64,经过\(x\).view、transpose与softmax将维度转换为shape均为\([1, 16]\)的\(x1、x2、x3、x4\),再分别与w对应相乘得到\(l, t,r , b\),结合式(2),\(x1、x2、x3、x4\)对应于\(P(y_i)\),由于\(\sum_{i=0}^nP(y_i)=1\),所以\(x1、x2、x3、x4\)中所有元素的和也均为1,比如\(x1\)=0.1+0.3+0.1+0.2+0.3=1,\(y_i\)对应于w,\(\sum_{i=0}^nP(y_i)y_i\)分别对应于w\(x1^T\), w\(x2^T\),w\(x3^T\), w\(x4^T\)。
由于softmax的取值范围为\([0, 1]\), 根据计算可以发现\(l, t,r , b\in [0, \text{reg_max}-1]\), 如果\(\text{reg_max}\)=16, 在特征图上所能预测的最大框\(prebox_{max}\)是\(l, t,r , b\) 都取15时,此时框的高度和宽度\(w_{max},h_{max}\)=30, 由于特征图相对于原始image的下采样倍数\(stride\in [8, 16, 32]\),如果我们取最大下采样倍数\(strid\)=32,则在原图上所能预测的最大box高度和宽度为\(w_{max},h_{max}\)=\(30*32\)=960,如果我们图像中的原始目标的宽度或高度过大,则会出现预测边界框小于原始目标的情况,比如如果我们有一个目标其实际的gt_box宽度为1000,但是我们实际能预测的最大宽度为960,这时就会导致预测不精准,此时则需要根据具体情况对\(\text{reg_max}\)作调整。 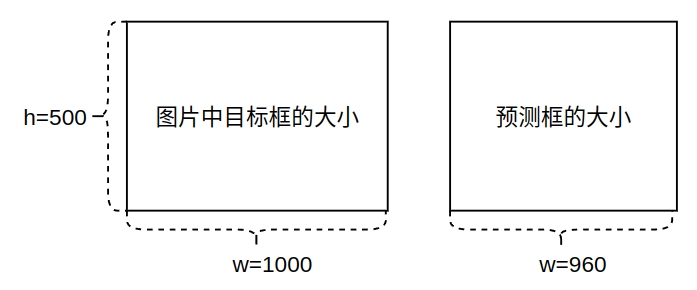
2.4 Loss
\[\mathrm{Loss}={\alpha\mathrm{L_{cls}}+\beta\mathrm{L_{ciou}}+\gamma \mathrm{L_{dfl}}}\tag{3}\] YOLOv8损失主要分为两部分,分类损失:\(L_{cls}\)和边框回归损失:\(L_{ciou}\)和\(L_{dfl}\), 分类损失\(L_{cls}\)为交叉熵损失,边框回归损失的\(L_{ciou}\)为ciou loss,\(\alpha\)、\(\beta\)、\(\gamma\) 表示各损失的平衡系数。\(L_{cls}\)即计算正样本损失也计算负样本损失,\(L_{ciou}\)和\(L_{dfl}\)只计算正样本损失。
1 | |
对于边框回归损失\(L_{dfl}\),模型所预测的是\([l_{pre}, t_{pre},r_{pre} , b_{pre}]\),原始目标框的输入是\([x_{tar1}, y_{tar1}, x_{tar2}, y_{tar2}]\),通过使用bbox2dist函数将\([x_{tar1}, y_{tar1}, x_{tar2}, y_{tar2}]\)转化为\([l_{tar}, t_{tar},r_{tar} , b_{tar}]\), 并将\([l_{pre}, t_{pre},r_{pre} , b_{pre}]\)和\([l_{tar}, t_{tar},r_{tar} , b_{tar}]\)作为计算dfl损失函数_df_loss的输入。代码_df_loss中\(wl、wr\)的计算如下图所示: 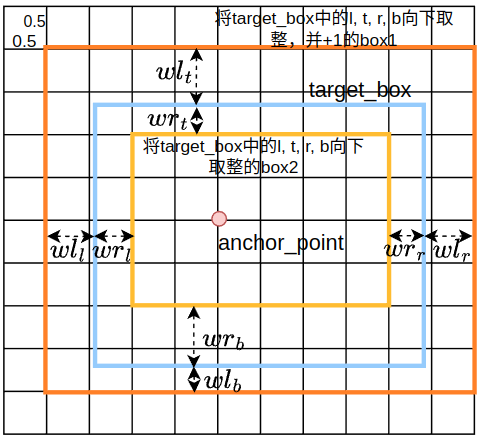
由于代码_df_loss中tl = target.long()会直接对target_box的\(l,t,r,b\)向下取整,向下取整会使原值的波动范围为\([0, 1]\)之间,1在图中正好是两个方格的宽度,\(wl_l, wl_t, wl_r, wl_b\)(\(wl = tr - target\),\(wl\)由\(wl_{l}、wl_{t}、wl_{r}、wl_{b}\)组成)显示了偏外侧的程度,值越小则说明target_box的对应边在两个方格中越偏外侧box1(对应于代码_df_loss中的\(tl\)),同理\(wr_l, wr_t, wr_r, wr_b\)(\(wr = 1 - wl\),\(wr\)由\(wr_{l}、wr_{t}、wr_{r}、wr_{b}\)组成)则显示了偏内侧的程度,值越小则说明target_box的对应边越偏内侧box2(对应于代码_df_loss中的\(tr\))。 我们再来看一下DFL的公式: \[\mathbf{DFL}(\mathcal{S}_i,\mathcal{S}_{i+1})=-\big((y_{i+1}-y)\log(\mathcal{S}_i)+(y-y_i)\log(\mathcal{S}_{i+1})\big)\] 其中: \(y_{i+1}-y\)对应于代码_df_loss中的\(wl\),
\(y-y_i\)对应于\(wr\),
\(log(\mathcal{S}_i)\)对应于: F.cross_entropy(pred_dist, tl.view(-1), reduction='none'),
\(log(\mathcal{S}_{i+1}\))对应于: F.cross_entropy(pred_dist, tr.view(-1), reduction='none')
2.5 正负样本匹配
正负样本匹配方面,YOLOV8和YOLOX均采用了动态的样本分配策略,YOLOV8采用了TOOD的 TaskAlignedAssigner方式,关于TOOD的详细讲解,可参考博文[9],YOLOX则采用了 simOTA方式,具体可参考视频[10]。
Reference
- https://github.com/ultralytics/ultralytics/ ↩
- https://juejin.cn/post/7187726947252699192/ ↩
- https://github.com/ultralytics/yolov5/issues/8785/ ↩
- https://arxiv.org/abs/2107.08430/ ↩
- https://zhuanlan.zhihu.com/p/599761847/ ↩
- https://www.bilibili.com/video/BV1JW4y1k76c/?spm_id_from=333.337.search-card.all.click ↩
- https://arxiv.org/abs/1904.01355/ ↩
- https://zhuanlan.zhihu.com/p/147691786/ ↩
- https://www.hbblog.cn/%E8%AE%BA%E6%96%87%E8%A7%A3%E8%AF%BB/TOOD/ ↩
- https://www.bilibili.com/video/BV1JW4y1k76c/?spm_id_from=333.337.search-card.all.click&vd_source=81b307c731d291353c2f2db16d04d4f8 ↩